Dex Tasks
Available Tasks
Dex task fall into 9 general categories listed and described below.
| TASK CATEGORY | DESCRIPTION |
|---|---|
| Database | These task pertain to operations performed on Relational as well as other databases. |
| Info | Task within this category pertain to gathering information about a incoming data or external datasets. |
| Input | Task pertaining to reading data into dex. |
| Output | Task pertaining to persisting data outside of dex. |
| Programming | Task which bridge dex to other programming languages. |
| Table Manipulation | Task for manipulating dex table data. |
| Utilities | Various utilities. |
| Visualization | Task for visualizing data. |
| Web View | Task which leverage an external Firefox or Chrome browser (via Selenium) to visualize data in facilities not available to the JavaFX WebView such as WebGL. Also used to prototype future dex templates prior to tight integration. |
Each task is accompanied with documentation which describes it's usage. Additionally, you may extend Dex with your own custom task. We will talk about this in depth in a later chapter.
Task Documentation
Each task is documented in the following format:
- DESCRIPTION - A short description of the task's purpose.
- CONFIGURATION - A comprehensive description of what configuration the task requires.
- INPUT - Information pertaining to any input requirements that the task has with respect to the Dex Stream. For instance, a task may require that a dataset consisting of 2 or more numeric columns be passed into the task as input.
- SAMPLE INPUT - And optional input sample.
- OUTPUT - Information pertaining to any outputs the task might have. Such as:
- Changes to the Dex Pipeline Stream
- SAMPLE OUTPUT - An optional sample output section.
- EXAMPLE USAGES - An optional section when one might use the component and how.
Task Pipeline / Workflow
Tasks are executed sequentially in what is known as the Workflow or Task Pipeline.
The initial task receives a state object as input, and returns a state object as output. The output from the previous task becoming the input to the current task. The initial task is passed an empty state object. Within our task documentation, we will simply refer to this as the INPUT and OUTPUT of the task.
This state object contains a current copy of the data within the pipeline. This data object is essentially a small table consisting of a header and a series of rows, much like a CSV or RDBMS table.
We will sometimes refer to this passing of data from component to component as the Dex Data Stream.
Workflow Execution
Example Workflow
Consider the following workflow:
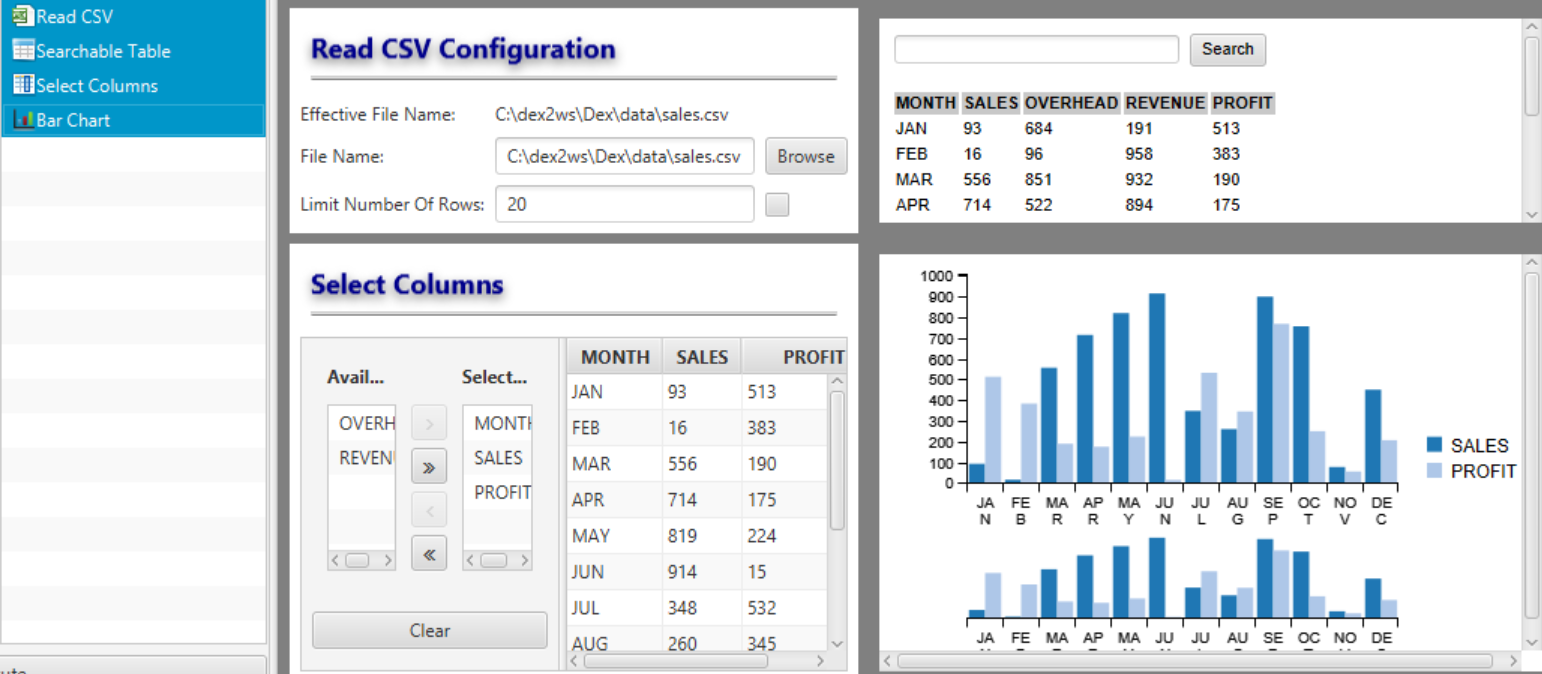
- Read CSV("sales.csv")
- Searchable Table
- Select Columns("MONTH", "SALES", "PROFIT")
- BarChart()
Read CSV
The first task is an input task called "Read CSV". In this workflow, since it is the first task, it receives an empty input object. When executed, "Read CSV" will read and parse the "sales.csv" file storing the data in the state object and returning this state object as output. This will, in turn, become the input for the next task in the workflow.
Searchable Table
The second task, "Searchable Table" simply receives the output from "Read CSV" as input. This task does not modify the state object, but simply displays a searchable table on the input it receives and returns this state unmodified to the next component in the flow; Select Columns.
Notice that there are 5 columns in the data as when Searchable Table is executed.
Select Columns
Select columns selects the MONTH, SALES and PROFIT columns, in that order. It filters out the rest of the data, displays the selected subset of the data within the execution window and then passes the filtered data to the next component via it's output state.
The input to the next Bar Chart component will only contain 3 columns. "MONTH", "SALES" and "PROFIT".
Bar Chart
Bar Chart receives input with 3 columns and displays MONTH vs SALES and PROFIT and then returns the state unmodified back to the pipeline. Since this is the last task in the workflow, nobody cares.
Dex Data Stream
The dex-data stream is simply a consistent input/output structure of type DexData.
DexData can be thought of as an in-memory CSV file with some convenience methods thrown in.:
DexData
Constructors
| CONSTRUCTOR | DESCRIPTION |
|---|---|
| DexData() | Constructs an empty DexData object with no headers or data. |
| DexData(List |
Constructs a DexData object with the supplied headers but no data. |
| DexData(List |
Constructs a DexData object with the supplied headers and data. |
Methods
| METHOD | DESCRIPTION |
|---|---|
| addColumn(colName, colData) | Adds the column named colName with data colData to DexData. If the column already exists, it will overwrite its contents. |
| addColumn(colName, i, colData) | Inserts column named colName with data = colData at index i within the DexData structure. |
| append(colName, colData) | Appends the column named colName with data colData to DexData. If the column already exists, it will overwrite its contents. |
| columnExists(colName) | Returns true if colName exists, false otherwise. |
| getColumn(columnNumber) | Given a column index, retrieve it's column values as a list of strings. |
| getColumn(columnName) | Given a column name, retrieve it's column values as a list of strings. |
| getColumnAsDouble(columnName) | Given a column index, retrieve it's column values as a list of doubles. |
| getColumnAsDouble(columnName, defaultValue) | Given a column index, retrieve it's column values as a list of doubles. If a value can't be converted to double, return defaultValue in it's place. |
| getColumnIndex(columnName) | Given a column name, return it's index. |
| getColumnMap() | Return a the dex data as a map where the name is the column name and the value is a list of strings representing the values of that column for each row. |
| getColumnNumber(columnName) | Given the name of a column, get it's column index. |
| getMapList() | Return a list of maps where each row is expressed as a map with it's column name as the key and the value of that column at that particular row as the value. |
| getMaxLengths() | Return a list of integers representing the maximum length of each column. |
| getNumericColumns() | Returns a list of column names containing numeric data. |
| getNumericData() | Returns a DexData object which only contains numeric columns. |
| groupByIndex(String groupName, String valueName, List |
Return a new DexData object grouped by the given groupedIndices with 2 new columns for the group name and value. |
| groupByName(String groupName, String valueName, List |
Return a new DexData object grouped by the given column names for the group name and value. |
| guessTypes() | Guess the datatypes housed in each column (string, date, integer, double). |
| max(colName) | Given the name of a column, return the maximum value of the column as a double. |
| min(colName) | Given the name of a column, return the minimum value of the column as a double. |
| normalize(columnName, rangeMin, rangeMax) | Normalize column columnName to the given range min and max. |
| renameHeader(columnIndex, columnName) | Rename column at columnIndex to columnName. |
| select(List |
Given a list of column names, return a DexData object which only contains those columns if present. |
| toString() | Return a string representation of DexData. |
Task Specification Overview
Each task is described with a short description, a screen shot where applicable followed by a list of options.
Input and output specifications are noted with a specialized shorthand described in the next section.
Input/Output Specification
Within the dex-data stream, the data within the table is stored as a string. However, certain task will expect data of stricter types. Here, we will descibe an efficient shorthand notation for expressing those requirements succinctly.
| SHORTHAND | DESCRIPTION |
|---|---|
| I | Integer Column |
| F | Float Column |
| N | Number Column |
| D | Date Column |
| S | String Column |
| CARDINALTY | DESCRIPTION |
|---|---|
| * | 0 or more. |
| + | 1 or more. |
| ? | 0 or 1 |
| EXAMPLE | DESCRIPTION |
|---|---|
| I+ | 1 or more integer columns. |
| SI+ | A string column followed by 1 or more integer columns. |